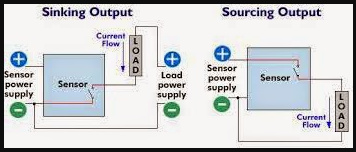
Sinking and sourcing are terms used to describe how an associated load (the device being turned on or off by the sensor) is powered in relation to the sensor.
Source and Sink Circuits
Look at this issue in simple terms. A basic circuit to show as an example is the circuit used to turn on a light. Why is there a light switch in a kitchen? Obviously so the light turns on and off…
A switch is used to control the power going to the light so it is not on all the time. If a switch was not needed, you would simply place 120 VAC to one side of the light and attach the other side to neutral (or ground) to complete the circuit.
A switch between either the line power (120 VAC) and the light or ground and the light controls the circuit, enabling it to turn on and off. If the switch is between the power and the light, voltage is sourced to the light, completing the circuit.
The light is always attached to the neutral (ground) line, so when the switch turns on, power is supplied (Sourced) to the light, turning it on. If the switch is between neutral (ground) and the light, the light sinks to neutral (ground), completing the circuit.
The light in this case is always attached to the power line, so when the switch is turned on, the neutral (ground) is connected (sinked) to the light, turning it on.
Sinking and Sourcing in Industrial Control Circuits
The kitchen light example simplifies the difference between sinking and sourcing circuits. Now look at today’s industrial control circuits using the same concept.
.
Control circuits need switches to provide automatic feedback on the status of a process. In the past, the feedback may have been as simple as an annunciator (light indicator) that would indicate the status of a process (i.e., a red light turning on to indicate a bad part, or that a tank needs filled).
As processes have become more automated, switch feedback was integrated into Programmable Logic Controller (PLCs) programs.
PLCs use switch feedback to automatically control circuits, i.e., if a liquid level switch turns on indicating a low level, automatically dispense liquid by turning a fill valve on, or if a cylinder switch turns on indicating end of stroke, automatically proceed with the next step which may drill a hole in a part. The control circuit uses the switch signal to turn on the next process.
Before PLCs, switch outputs would typically turn a control relay on or off to control the next phase of the process. If the switch attaches between the power supply and the control relay, the circuit is a sourcing circuit.
If the switch attaches between the control relay and ground, the circuit is a sinking circuit. The decision regarding which circuit to use may have been made for safety concerns (to reduce chance of electrical shock). Or perhaps a standard was adopted at a factory specifying that all circuits would be wired the same way, whether it be sinking or sourcing.
PLCs work a little differently than your kitchen light or a simple control relay, however. PLCs were developed to automate and simplify control relay circuits, eliminating much of the wiring and adding greater flexibility.
PLCs can manipulate control systems programmatically rather than by hard wired control relays. PLCs use input cards to read the feedback of the control circuits. Input cards connect internally to power or ground.
To turn an input card “on”, connect power or ground to the input dependent upon which input card is in use. PLC programs use this “on” state signal to determine when to proceed with the next step of the process. To control the “on” state, place a switch between the power or ground and the input card. An input card wired internally to ground is typically regarded as a sinking input card.
A sinking input card requires power to be sourced to the input to turn it “on”. If the input card connects internally to power, it is typically regarded as a sourcing card.
A sourcing card input requires a ground connection to turn it “on”. Think of the input card as the kitchen light, except in this case the light comes pre-wired to power or ground.
Solid State Switches with Sinking and Sourcing Circuits
When circuits use a simple two-wire switch, such as a reed switch, to control the PLC input signal, the circuits may implement the two-wire switch in either a sinking or sourcing circuit.
However, when the circuit uses existing solid state switch technology (developed to correct some of the problems associated with reed switches, i.e., contact bounce, slow signal response, lower life) to control the PLC input signal, difficulty and confusion quickly emerge.
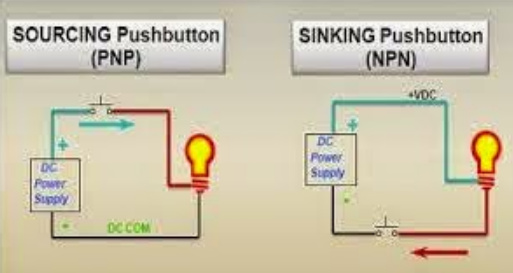
The confusion emerges because, until now, Solid State switches were traditionally three-wire devices that had to be designed to operate specifically in a sinking circuit or a sourcing circuit, but not both.
The input wire connects to the power source (typically 24 VDC) and is used to power the switch, the ground wire connects to ground, and the output wire typically connects to the PLC input card, supplying the control signal that will turn the input card “on”.
Existing solid state switches can only be used in one type of circuit because they use an internal transistor as the switching element.
Transistors come in two basic styles, NPN and PNP. Sinking outputs use NPN (Negative-Positive-Negative) transistors, and sourcing outputs use PNP (Positive-Negative-Positive) transistors. This fact requires switches and PLC input cards to match. If the wrong switch is used, the PLC will not read the switch output.
This requires designers to be careful when specifying the type of switch to use for their control circuits and automation systems. Specifying the wrong switch may result in project delays, return charges, and changes to purchase orders which can all be costly.
Likewise, when a switch fails there may be confusion as to which type of switch is needed. Maintenance personnel may order the wrong type of switch, causing increased down time and cost.
To further exacerbate the problem, not all PLC manufacturers label their input cards the same. Some manufacturers label their input cards that are internally wired to power “sinking cards”, and label their input cards that are internally connected to ground “sourcing cards”, causing even more chances for error. Now you can see why there is much confusion in the market regarding the sinking and sourcing issue.
Difference between source and sink
Sinking and sourcing are terms used to describe how an associated load (the device being turned on or off by the sensor) is powered in relation to the sensor.
Sinking, the more widely used of the two, involves the switching of load current (power) supplied by a power source external to the sensor. In a sinking configuration, current passes through the load first, through the output switch of the sensor second and lastly to ground.
A sensor with a sinking output switches the ground, or negative, leg of the circuit. In contrast, sourcing refers to a configuration in which the sensor is the source of the current required to power the load.
In a sourcing situation, current supplied by the sensor passes through the load second and then to ground. A sensor with a sourcing output switches the positive leg of the circuit.